
by Azra Hussain
As the internet grew steadily throughout the mid to late 1990s, it brought with itself the major upside of better and faster communication. Instant and efficient communication took place of more redundant and now mainly useless means of communication. The internet was not, however, designed with the aspects of anonymity and privacy of the individual in mind, which left most of the data open and vulnerable to attacks, manipulation or theft.
An individual’s internet information could be recorded and traced back to them. This fact concerned certain groups, like the cypherpunks, individuals who advocated for the increased use of encryption and coding to ensure the privacy and security of the user data. Another concerned party in the 1990s was the United States Federal Government.
Onion Routing
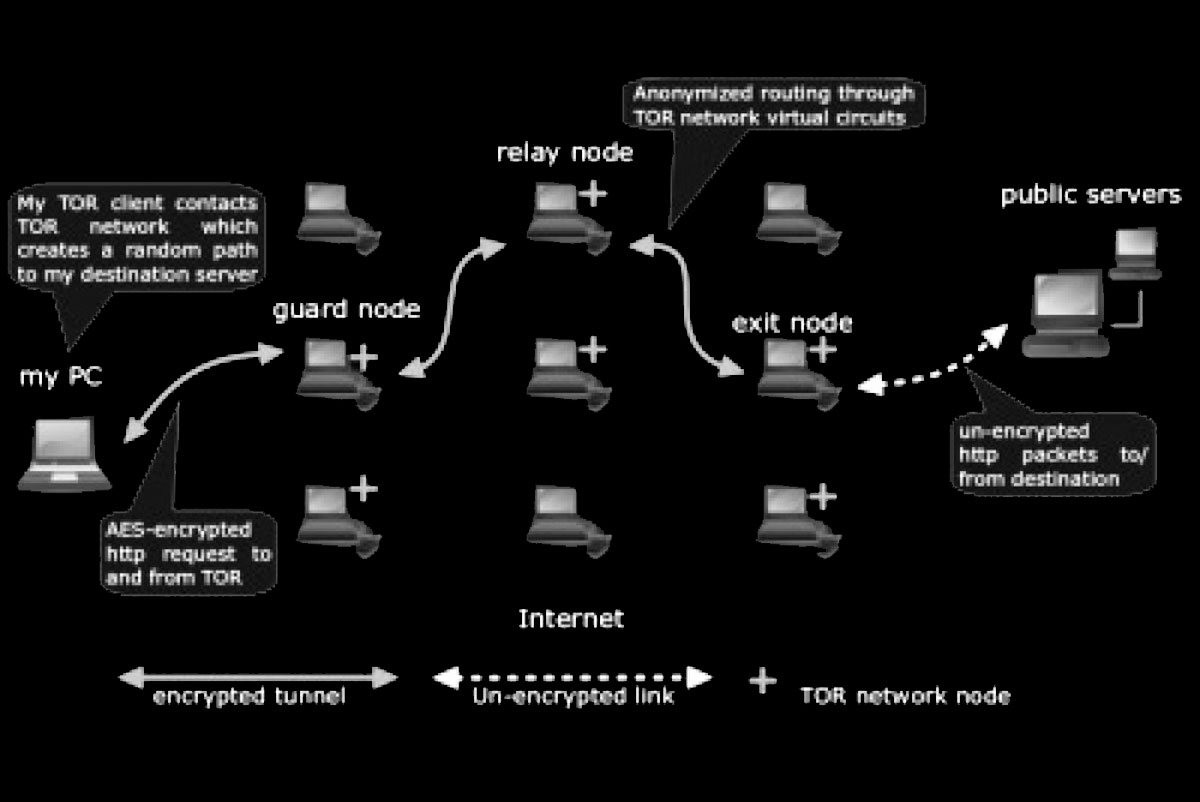
To find a solution to this problem, a group of scientists and mathematicians working for the American Government, known as the Naval Research Laboratory (NRL), found themselves working on a technology known as Onion Routing. This technology would allow bi-directional communication in which the source and destination could not be determined through a mid-point. In simpler words, Onion Routing gave the user the privacy and liberty of browsing or writing anything on the internet without the information being easily traceable back to them. Anyone could communicate with anybody else without his or her information and messages being open and available to anyone else.
In order to achieve this, an overlay network had to be established. An overlay network is just a network which is built on top of another network, which in this case, was the internet. Instead of using the normal, unencrypted internet, the surface web, the Onion Routing technology now used an encrypted, secure network.
There are many types of overlay networks, but the network the NRL was working on at that point of time falls into the category of a Darknet. Darknets can only be accessed through a certain type of software and/or administrator rights. However, the United States Government soon ran into a problem, best explained by Roger Dingledine, co-founder and director of the TOR project: “The United States Government can’t simply run an anonymity system for everybody, and then use it themselves only, because then, every time a connection came from it, people would say, ‘Oh! It’s another CIA agent looking at my website.’,” he told a gathering that broke into laughs. “So you need to have other people using the network so that they blend together.”
According to Dingledine, if the network was to be made anonymous in every sense of the word, the United States Government could not be the only ones using it. There had to be more common people using it. This would make it impossible for anyone to determine whether the person using the network was an agent working for the government or just an individual who wants to secure himself. To achieve this anonymity they had in mind, the government had to make sure that the software was made available to everybody. Hence, the NRL was forced to release their onion routing technology to the general public. It was released under an open-source licence and was known as ‘TOR’, which stands for The Onion Router.
Today, millions of people use TOR for almost anything, from sending emails and messages, watching videos, buying and renting things online, to hiring hit men, buying drugs and weapons, leaking sensitive information, or unveiling scandals hidden from the general public.
Despite being the most popular, TOR is but one of the many Darknets present on the World Wide Web. All these Darknets, when put together, form the dark web, which in turn forms a very small portion of the deep web. The deep web consists of all the pages and sites on the internet which cannot be indexed by a search engine. Somebody’s Gmail inbox, an unlisted YouTube video, a private Instagram account, or a webpage present on the dark web are a few examples of the constituent pages present in the deep web. Basically, everything that is password and/or paywall protected can be classified as deep-web content, simply because of search engines like Google or Bing! cannot index or display them.
This makes it obvious that the deep web has much more content than the surface web. However, it is impossible to determine the size or expanse of the deep web because of its very nature. An article published by the Journal of Electronic Publishing in its 7th volume suggests that the public information available on the deep web is 400 to 550 times larger than the surface web and that it contains 7,500 terabytes of information in comparison to the 19 terabytes of information that is accessible through surface web browsers.
“Sixty of the largest deep-Web sites collectively contain about 750 terabytes of information — sufficient by themselves to exceed the size of the surface Web forty times,” the article reads.
However, this study was conducted in 2001 and is over a decade old. Even if it was accurate at that time, it has now grown outdated and is no longer even a proper estimation of the size of the web. All that is known for certain is that the deep web accounts for the vast majority of the internet and the data present on it.
In conclusion, there are three parts of the internet:
1. The surface web, which is part of the internet that can be indexed and displayed by commonly used search engines like Google, Bing!, Yahoo, etc.
2. The deep web, which consists of all the data that cannot be indexed by a search engine. This includes paywall and/or password protected content, webmail, unlisted YouTube videos, dynamic pages, databases, Netflix, online banking and shopping, etc.
3. The dark web, which cannot be accessed by regular browsers or software and can only be accessed through special software and/or special authorization rights. The data present on the dark web is heavily encrypted and password protected in order to prevent disclosure of an individual’s IP address and hence identity.
(This is the second part of three-part series on internet. The first part is here. The third part is here)













